Project Title
How lowballing on Facebook Marketplace ruined my week
Overview
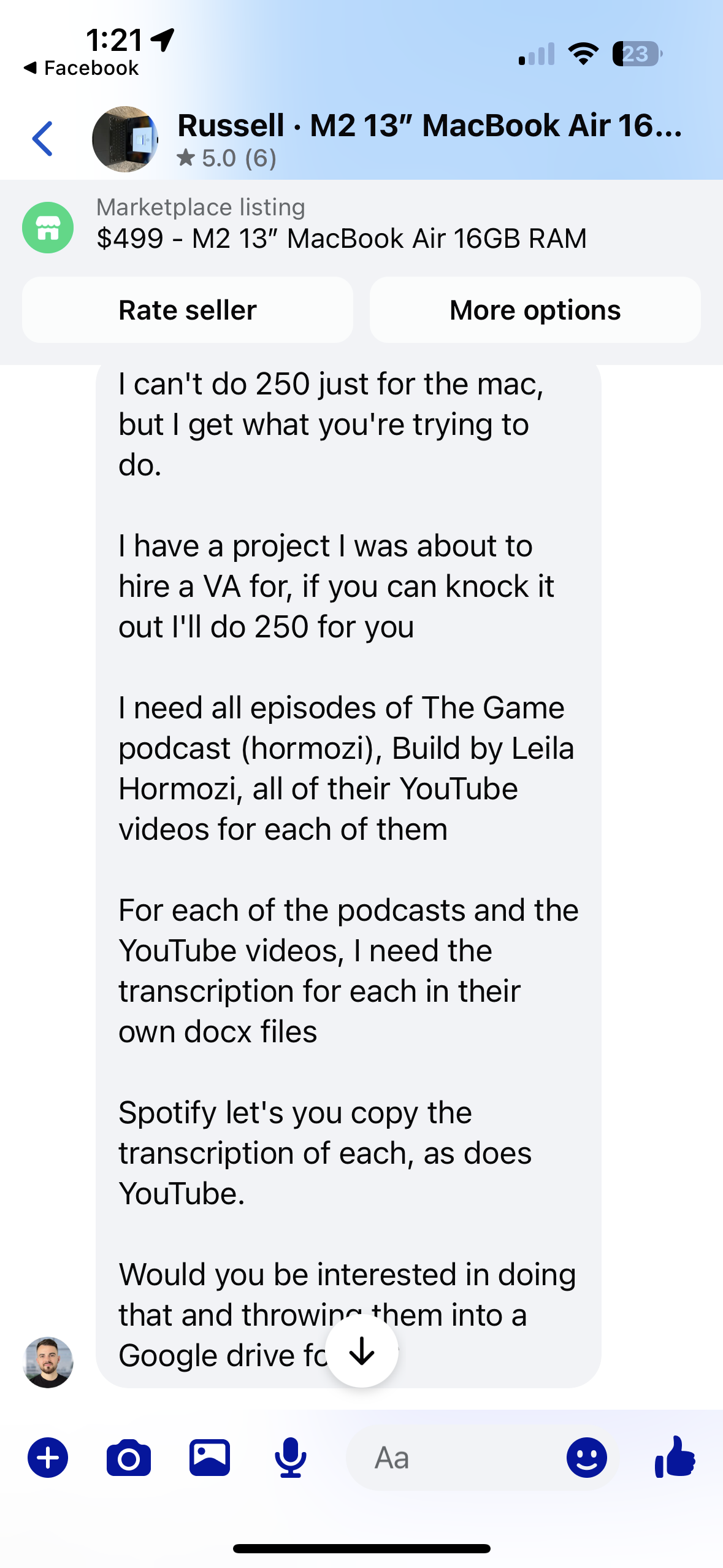
Along my Linux journey, I have come to understand one far distant goal that I will one day reach and definitly post about on here: use linux on a macbook with apple silicon. For a long time now, I have envied the sleek design and feel of apples products, but find MacOS too far away from my learned habits from Windows and Arch. Through the power of Asahi Linux, it is now possible to port Arch linux (I use arch btw) onto Macs with Apple's own silicon allowing for both the look, feel, and amazing battery life of Apple's laptops, along with the customization and flexibility of the fork of Arch I use, EndeavorOS. This led to a frantic search on Facebook Marketplace and a bout of lowballing that surely frustrated many the Macbook owner. I stumbled upon a M2 Macbook air with 16gb of ram that was selling for $500, already a low used price, and I offered $250. His reaction was not at all what I had expected. As seen from the DMs in the image, he gave the strange request of accepting the price upon my completion of a coding project. All I needed to do was transcribe a bunch of youtube videos and spotify podcasts indo docx files for him to help build a rag (retrieval-augmented generation) agent for him. I chose not to question why and immediatly accepted thinking it could not possibly be that difficult.
Setup
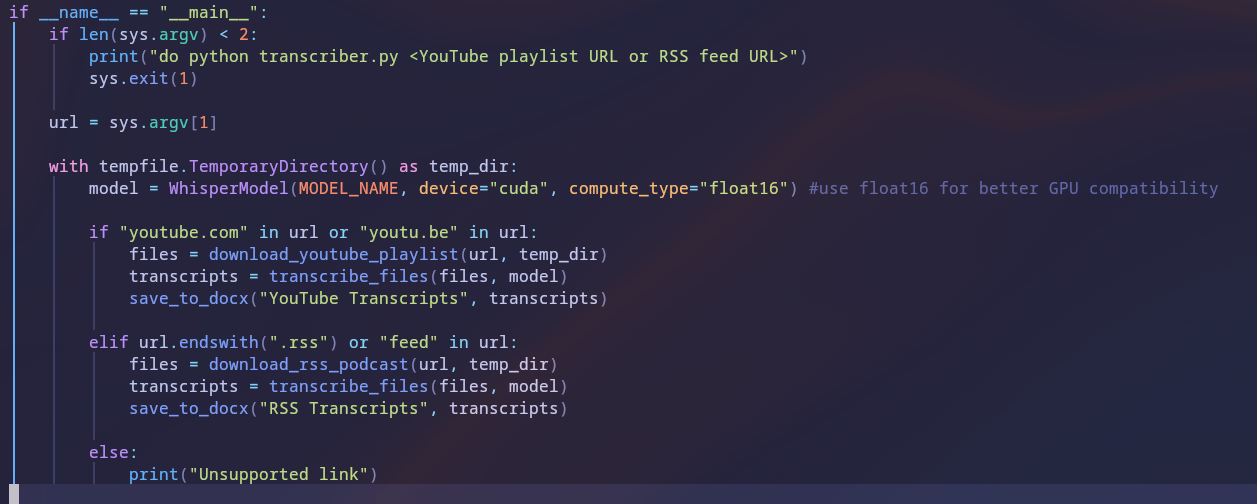
I had heard of a audio transcription model from OpenAI called Whisper, and upon further research found a reimplementation called faster-whisper which by the naming seemed like a better option. The other thing I knew was that the audio we needed to scrape either came from Youtube or Spotify. I quickly realized spotify would hate this but discovered all the podcasts that were requested for transcription had a public RSS (Really Simple Syndication) feed. This is convienient if you think of the RSS feed as the trunk of the tree that feeds branches like Spotify and Apple Podcasts. Instead of having to deal with spotify, I'd just take the audio files from the public access point. Youtube also wasn't going to be a huge fan of me downloading lots of files, but the handy yt-dlp team constantly reverse engineer the ever changing request pattern and I never got any trouble from them. After settling on the model and the means to grab our content from the web I researched the relevant packages to build this in python and booted up vim to get to work. The structure of the program ended up being very simple with only 4 functions: download youtube audio, download RSS feed audio, transcribe the file, save to a .docx file. While it isn't that simple the full code is available on my github.
Bugs
Of the many normal bugs encountered by this program, the ones I found mostly infuriating were those that were obviously my fault. I don't code in a virtual environment, and so getting the transcription model set up properly was very difficult which will become a very key point in the next section. Our model, faster-whisper, requires ctranslate2 and not PyTorch for inference like its big brother "Whisper". While I love linux, its times like this when I'm trying something not well documented when it becomes a real nightmare. I ended up having to make a custom cmake build file in order for it to load at all. Note here that I was primarily concerned about getting the model loading at all, and so was testing the setup on the default compute device, the CPU. It also turned out I needed different compiler versions for all of the relevant backend c++ code to not freak, forcing me to compile the gnu compiler compilation version 13 as some behavior I don't at all understand had changed between versions 13 and 15. After spending 2 hours compiling this from binary because no pre-built version existed for my linux distro, I was lazy and snagged a pre-built wheel of faster-whisper leading to this next section "Despair".
Despair
After debugging, dealing with version compatability, and figuring out the best way to iterate through a youtube playlist so that I wasn't downloading all of the audio from a given playlist first, I transcribed my first video with amazing quality with the "tiny" model. However, the program ran at nearly real time meaning I should just type the transcripts manually. Thus, the journey of GPU acceleration began. This was the most humbling experience of my entire life. I initially thought I could just change the device to "cuda" and it would magically send all the math to be done in parralel on my beefy 3080 Ti and I would laugh as I tore through hours and hours of content in seconds. This was not the case. I got the mysterious "Conv1D on GPU currently requires the cuDNN library which is not integrated in this build" error that would plague me for days. What is cuDNN? What build is it not integrated into? I spent the next few days hating myself for that cmake file I made thinking I had messed up the ctranslate2 backend build. I spent a embarrassing amount of hours trying to figure out what the issue was, I could not figure it out. I know nothing about c++, chatGPT even gave up on me instead blaming it on my operating system. And so in my moment of dispair, I loaded the code into PySpark in windows and it ran like a dream. I thought I had finally done it, GPU accelerated we were transcribing about an hour of audio per minute. That is insanely fast. I was patting myself on the back and calculating my total time I'd need to leave the computer alone to download and transcribe the relevant files when I encountered a sobering reality. It was 1700 hours of audio. Even at an hour per minute thats a little over 28 hours of pure transcription which wasn't even the biggest issue. Downloading the audio took longer than transcribing it. At that moment I knew it was over. It was now Thursday and I had planned to pick up the Macbook on Saturday. I doubt I would have had all the transcriptiosn by Monday that next week. I moped and begged but alas after I said I could not make the meetup I never saw another response from the mystery Macbook seller.
Resolution
After I got over the inital pain of failure, my dear friend, who is also named Luke, showed me Claude Code which could look into my files directly to build out code for my next project. I decided to move back into linux, paid for $5 worth of Claude Code API credits, opened Claude into my root directory, and told it to fix my cuDNN integration issue, leave no stone unturned. Within minutes, Claude had found the problem. THE PREBUILT WHEEL OF FASTER-WHISPER HAD NO CUDNN OR CUDA INTEGRATION. I had never even considered that someon would want to use a transcription model without GPU acceleration. Claude immediatly fixed the issue and thus I was resolved of my doubts in Linux. Linux isn't buggy. "It Just Works". Maybe I didn't get that Macbook for $250 but I damn sure did learn a lot. Above all else I had gained a new friend, Claude Code. I promise you've never seen anything like it. Claude Code working in the terminal pointed at the root directory seems like risky, but it makes you feel alive and really brings out that "will I or won't I corrupt my OS" vibe that I love. Check out the code on my GitHub if you want, reach out if you actually need help implementing this, and above all else contact me if you'll sell me an Apple Laptop.